Emoji Search 🔮 Creating, Deploying and Evaluating a Machine Learning Service

A tech focused education and services company.
Computers can model language in such a way that they can perform well on tasks such as text similarity. In this article, I attempt to create an Emoji suggestion tool which uses vector word embeddings to determine the relevant Emoji recommendation. I also deploy the machine learning model as a service on AWS and dive into cost estimations. A live example of the service can be found on the T3chFlicks site; all the code is open sourced.

🔗 Find All the Emoji Search Code On Github📔
Emoji 😂 ❤️
Emojis are common-place in internet communication, the tiny intricate pictograms have opened the door to quick thumb tap summarisation.
Computers represent Emojis using the Unicode Standard:
Code: U+1F600 (Unicode)
\xF0\x9F\x98\x83 (UTF-8 Bytes)
Emoji: 😀
Description: grinning face
The popularity of Emojis differs massively across societies and cultures, but Unicode publish some stats on their proportional use:
](https://cdn-images-1.medium.com/max/3200/1*N0_wL0A3CIm-qInu9ioU2Q.png) *
*
https://home.unicode.org/emoji/emoji-frequency/*
What do we want?
During project conception we decided that we wanted the following:
To enter a search text and in response get a list of similar Emojis
To run a machine learning model in AWS Lambda
To use this service to improve the efficiency of adding Emojis to our articles.
Build — Emoji Search
To be able to search text and be suggested the most similar Emojis, we need to find the similarity of the search text with the Emojis.
First we must try to compare apples with apples, and luckily Emojis in the Unicode Standard have a short description of the image, using these we can compare the two strings search_text vs. emoji_description .
One current technique for modelling language is using word embeddings — a vector space where the dimensions and relations represent meaning between words.
We really recommend the following video for understanding the concept of embeddings:
Searching Emojis using Word Embeddings
We’re using Google News Vectors from 2019 as a language model, this isn’t necessarily the best choice (newer models exist such as Bert), but it will definitely be up for the task. A condensed version of the model can be found here.
A simple way to investigate the learned representations is to find the closest words for a user-specified word. [source]
We first load the model in the *word2vec* format:
import os
import gensim
GOOGLE_NEWS = os.path.join(FIXTURES_FOLDER, "GoogleNews-vectors-negative300-SLIM.bin.gz")
model = gensim.models.KeyedVectors.load_word2vec_format(GOOGLE_NEWS, binary=True)
This model is used to process Emoji data. Luckily, all the information we need is found in a Python library called emoji_data. We start by extracting the Emoji text into a Pandas data frame. For simplicity, we only keep the standard yellow Emoji set.
from emoji_data import EmojiSequence
d = {'emoji': [], 'description': []}
for (emoji, emoji_meta) in EmojiSequence:
d['emoji'].append(emoji)
d['description'].append(emoji_meta.description)
df = pd.DataFrame(d)
df['description'] = df['description'].str.split(' skin tone').str[0].str.replace(':', '').str.replace(',', '')
df = df.drop_duplicates(subset=['description'])
---------------------------------
emoji description
👨❤️👨 [couple with heart man man]
The vector of each word in the description text for the Emoji is averaged into a vector for that Emoji:
def process_words(text):
words = text.split(" ")
word_vectors = [ model.syn0norm[model.vocab[word].index] for word in words if word in model.vocab]
if len(word_vectors) > 0:
mean_vector = np.array(word_vectors).mean(axis=0)
unit_vector = gensim.matutils.unitvec(mean_vector).astype(np.float32).tolist()
else:
unit_vector = np.zeros(model.vector_size, ).tolist()
return unit_vector
df['vector'] = df['description'].apply(process_words)
For example, using the search text ‘dog’ and cosine similarity of emoji_vector vs. search_vector we can establish the similarity of all the Emojis. We can then select the top two.
from sklearn.metrics.pairwise import cosine_similarity
def find_similarity_to_search(search_vector):
def func(emoji_vector):
b_emoji = np.array(emoji_vector)
cos_sim = dot(search_vector, b_emoji) / (norm(search_vector) * norm(b_emoji))
return cos_sim
return func
search_text = "dog"
search_vector = np.array(process_words(search_text))
find_similarity_to_search = find_similarity_to_search(search_vector)
df['similarity'] = df['vector'].apply(find_similarity_to_search)
df.nlargest(2, 'similarity')
--------------------
emoji similarity description
🐕 1.000000 dog
🌭 0.775372 hot dog
Whilst that example is rather plain, here is another that made us chuckle and think the service works well:
search: "giant obstacle"
-------------------
emoji similarity description
🦣 0.416749 mammoth
🤘🏽 0.352729 sign of the horns medium
🧗🏽♂️ 0.351723 man climbing medium
🐉 0.330775 dragon
🗺️ 0.330681 world map
Architecture of the Emoji Search API
The Python script above can be run on the Cloud and made accessible via the internet as an API. We use AWS as our Cloud provider with CloudFormation to write infrastructure as code.
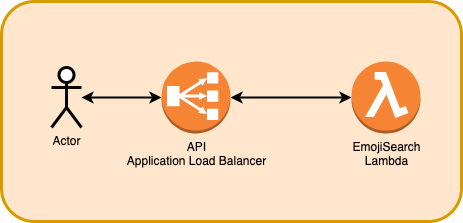
The architecture uses an Application Load Balancer with Lambda as an API, we have already discussed this in a previous article: Cheaper than API Gateway — ALB with Lambda using CloudFormation An alternative to API gateway is Application Load Balancer. ALB can be connected with Lambda to produce a highly…t3chflicks.medium.com
AWS Lambda supports using docker containers, this allows us to run the Lambda locally for development and testing. The script is packaged into the docker container with the Google News Vectors as this makes it accessible at runtime without requiring downloading from S3 or EFS. The Lambda required 1.5GB memory to run the model.
Deployment of the Service
Deployment pipelines can be created on AWS using CodePipeline. This process is triggered by commits to a Github repository. It follows a sequence of defined steps, beginning with provisioning the infrastructure for the service, then testing the code, building a docker container and finally updating the Lambda:
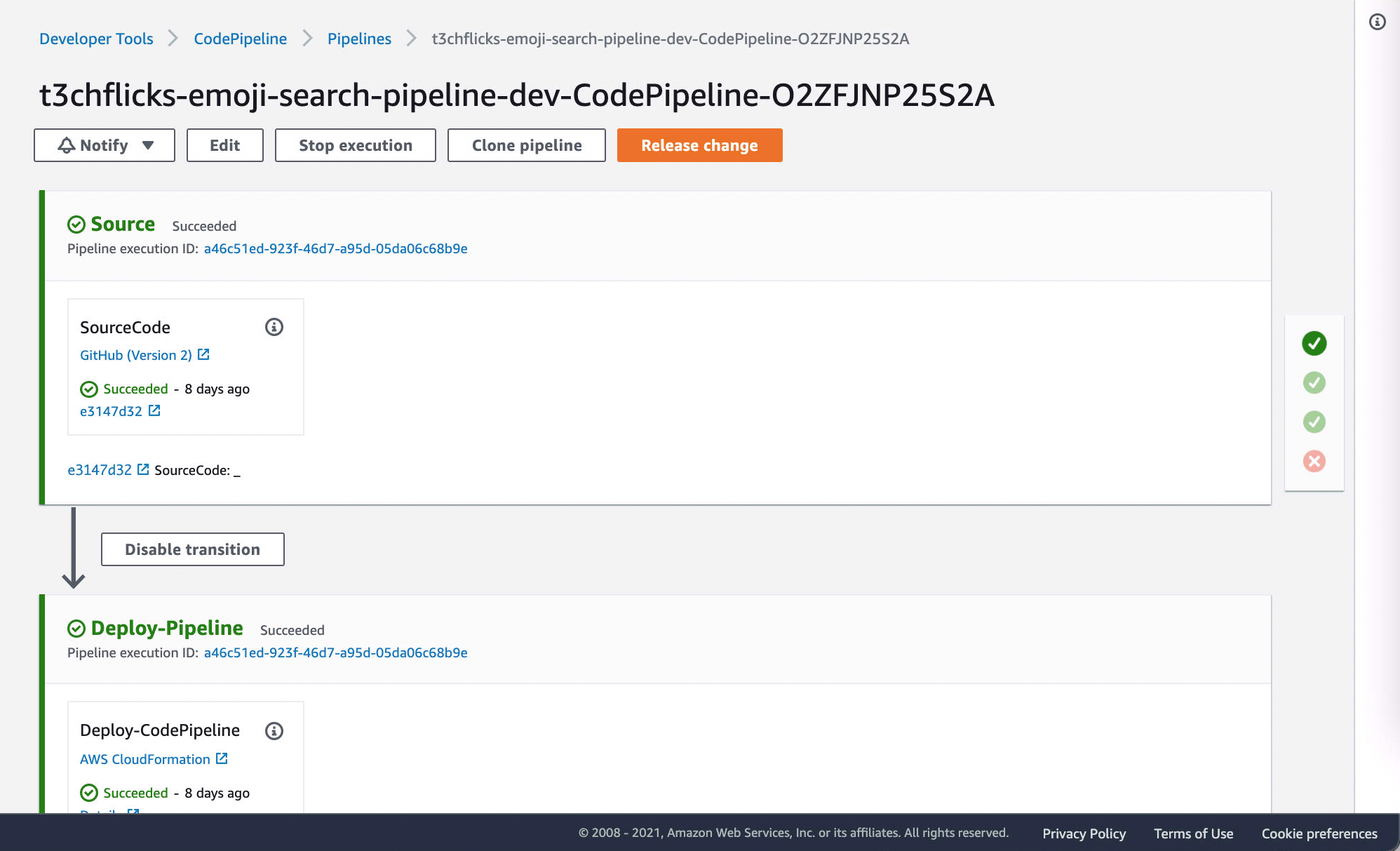
Thanks to the super developer James Turner for showing us how to create CI/CD pipelines on AWS that are triggered by Github commits: From GitHub to Continuous Deployment in 5 Minutes How to go from having a Github repository to having a CD pipeline in AWS where you can run tests, and continually…aws.plainenglish.io
The Interface
We made a widget that allows users to easily play with the API and view the JSON schemas which define the input and output:
 to play!](https://cdn-images-1.medium.com/max/4620/1*UzyjbN5_1Xn7N4WUH9YzzA.png) *
*
This widget allows you to interface with the API. Visit https://t3chflicks.org/services/emoji-search to play!*
The programmatic use of the API is as follows:
url '[https://api.t3chflicks.org./emoji-search/recommendations'](https://api.t3chflicks.org./emoji-search/recommendations') \
-H 'content-type: application/json' \
--data-raw '{"key":"4aac6db6d8dfc3fa7693b8b5918b3d548e3c92ebd70832447bab247a1c0b0b477d9107ecfe05f8153ef6d3d848614de3cb8bcf42e256aac1444eb828be1f4083","search":"Dog","quantity":5}' \
--compressed
>>> {"most_similar": [{"score": 0.6978708999734073, "emoji": "\ud83d\udc15", "description": "dog"}, {"score": 0.5574100960192504, "emoji": "\ud83c\udf2d", "description": "hot dog"}, {"score": 0.5498123048808492, "emoji": "\ud83e\uddae", "description": "guide dog"}, {"score": 0.5273177453464898, "emoji": "\ud83d\udc08", "description": "cat"}, {"score": 0.4822364083781162, "emoji": "\ud83d\udc15\u200d\ud83e\uddba", "description": "service dog"}]}
🤖 The widget can be found on our site 🤖
The Cost Estimation
Determining the cost of running the Emoji Search service is similar what we have done in a previous article: Giving away free APIs without going broke. I like to write articles on Medium. I also want to share the same articles on our own site without having to rewrite…t3chflicks.medium.com
For the architecture described the cost equation is:
Total cost = Application Load Balancer cost + Lambda cost
We will continue with the assumptions of **4350 Requests/Month** from 100 users using their 100 free credits.
Lambda Cost
The Emoji Search Lambda has the following response stats:
542 ms on average @ 1536 MB memory (cold start 1362ms)
These numbers can be plugged into the Lambda cost calculator:
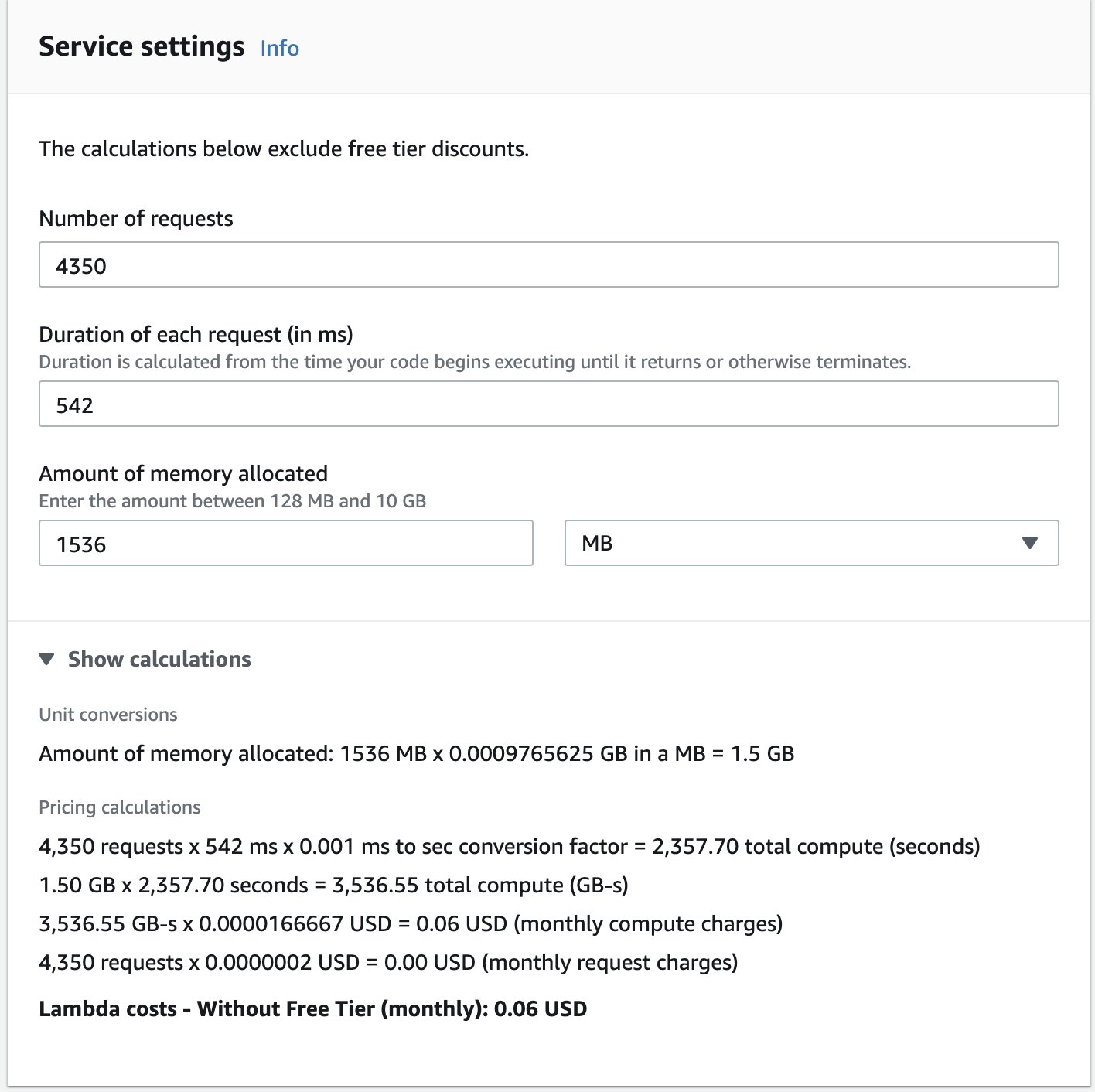
A nearly negligible cost at $0.06 / Month. However, when scaling into the millions of requests, the service does begin to become quite costly:
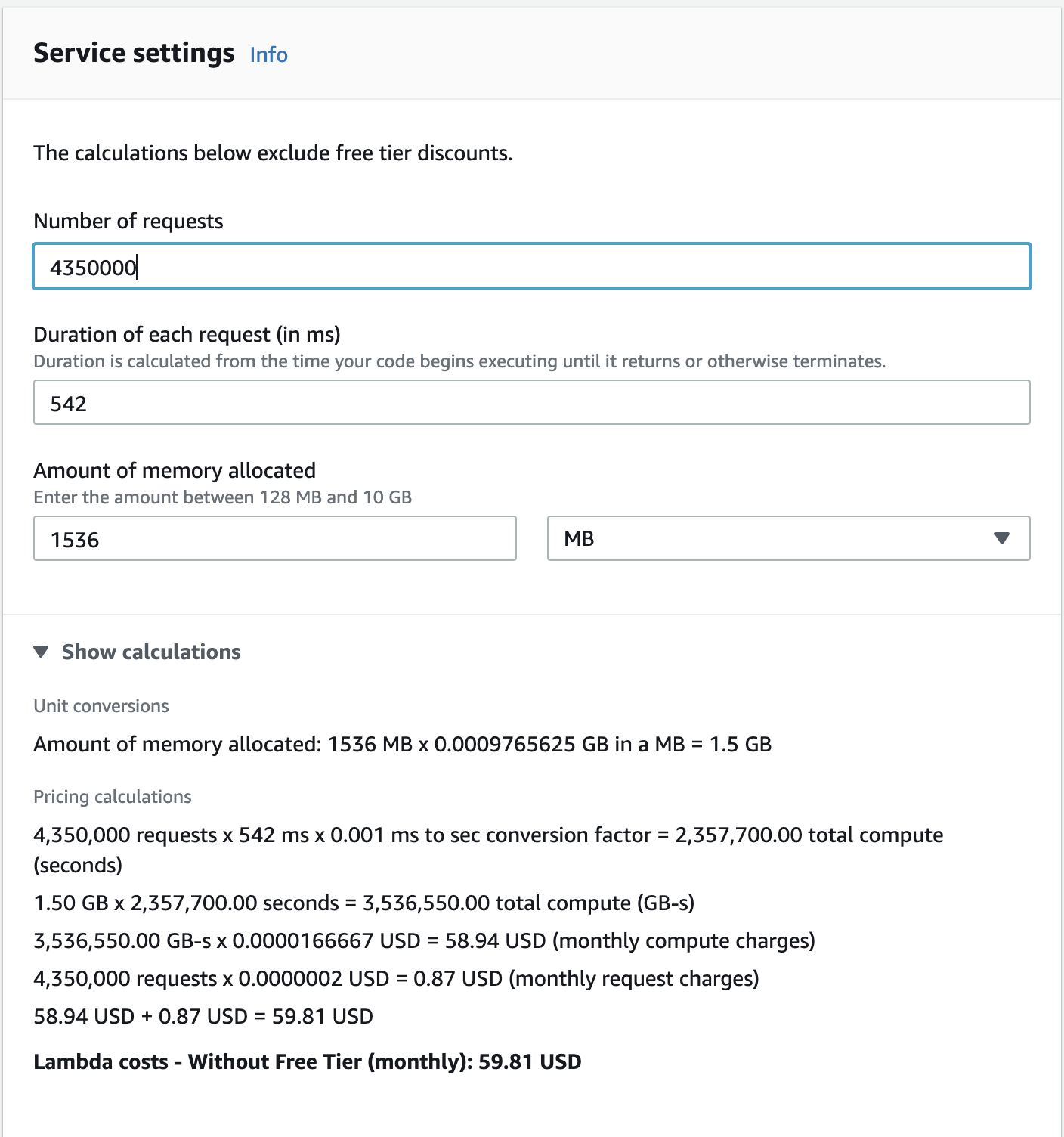
In the scenario that we did receive this sort of request rate, we would undoubtably have to rearchitect.
Application Load Balancer Cost
The Load Balancer will process requests of the following size:
Processed bytes = (167B request + 172B response) * 4350 requests = 1,474,650B** = **1.475MB = 0.001475GB
These numbers can be plugged into the Application Load Balancer cost calculator:
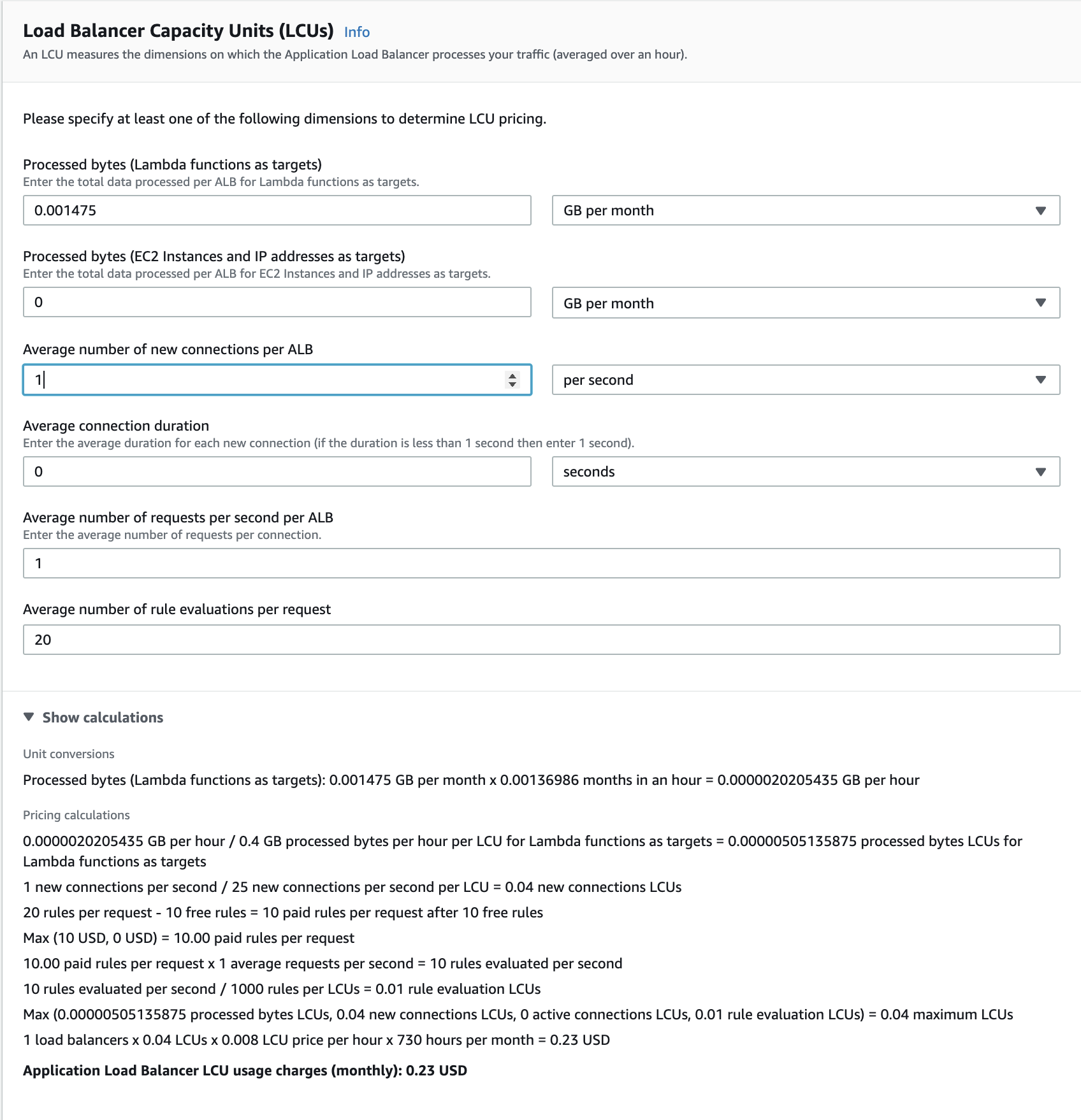
Total ALB Cost = (ALB/month) + (LCU/month)
Total ALB Cost = $0.23 +(730hours/month * $0.0252/hour) = $18.63
Total Cost
At a request rate of 4,350 per month, the service can be estimated to cost:
Total Cost = Application Load Balancer cost + Lambda cost
Total Cost = `$18.63 + $0.06 = $18.69
As many services can share the same ALB, their cost will be shared across projects. A cheaper alternative would be to use API Gateway.
We do not expect this much traffic and simply want to expose the service for fun.
We have created a Cost Budget with alarms that trigger when the service is going to exceed the expected cost.
Conclusion
At T3chFlicks we want to share, this is why you’ll find the code that created this project is open sourced. We’d love to hear from experienced developers / business owners on how they managed to run a successful SaaS, please reach out!
Thanks For Reading
I hope you have enjoyed this article. If you like the style, check out T3chFlicks.org for more tech focused educational content (YouTube, Instagram, Facebook, Twitter, Patreon).

